ModEst:Computationeel model: verschil tussen versies
| (2 tussenliggende versies door dezelfde gebruiker niet weergegeven) | |||
| Regel 19: | Regel 19: | ||
::* Controleer of het systeemgedrag plausibel is, gegeven de invoerwaarden. Bedenk bij welke parameterwaarden je bijzonder gedrag kunt verwachten (bijv. stroomsnelheid = 0, vaarsnelheid = 0 of koersverandering = 0), bedenk hoe de grafiek er dan zou moeten uitzien, en test die [[Empirische cyclus|hypothese]] vervolgens door het model met die invoerwaarden door te rekenen. | ::* Controleer of het systeemgedrag plausibel is, gegeven de invoerwaarden. Bedenk bij welke parameterwaarden je bijzonder gedrag kunt verwachten (bijv. stroomsnelheid = 0, vaarsnelheid = 0 of koersverandering = 0), bedenk hoe de grafiek er dan zou moeten uitzien, en test die [[Empirische cyclus|hypothese]] vervolgens door het model met die invoerwaarden door te rekenen. | ||
====Probabilistisch model==== | |||
Bij implementatie van een ''probabilistisch model'' zijn nog extra handelingen nodig: | Bij implementatie van een ''probabilistisch model'' zijn nog extra handelingen nodig: | ||
| Regel 29: | Regel 30: | ||
De door jou gekozen lengte van de tijdstap en de lengte van de simulatieperiode (het aantal rijen voor de tijdsafhankelijke variabelen) kun je wel al in §3 onderbouwen, zéker wanneer de (minimale) simpulatieperiode direct verband houdt met de onderzoeksvraag (bijv. "Hoe ver is het bootje gevorderd na 10 minuten varen?"). In §4 moet je er altijd over rapporteren omdat tijdstap, simulatieperiode, opstarttijd en aantal replicaties onderdeel zijn van het [[experimenteel ontwerp]]. | De door jou gekozen lengte van de tijdstap en de lengte van de simulatieperiode (het aantal rijen voor de tijdsafhankelijke variabelen) kun je wel al in §3 onderbouwen, zéker wanneer de (minimale) simpulatieperiode direct verband houdt met de onderzoeksvraag (bijv. "Hoe ver is het bootje gevorderd na 10 minuten varen?"). In §4 moet je er altijd over rapporteren omdat tijdstap, simulatieperiode, opstarttijd en aantal replicaties onderdeel zijn van het [[experimenteel ontwerp]]. | ||
====Gevoeligheidsanalyse==== | |||
[[Bestand:gevoeligheidsanalyseBootje.png|thumb]]Voer tenslotte een [[gevoeligheidsanalyse]] uit. Rapporteer daarover in de vorm van een [[tabel]] die voor '''elke''' invoervariabele laat zien hoe sterk de uitvoervariabelen veranderen als gevolg van een kleine verandering (typisch +20%) t.o.v. een gekozen basisscenario.<br><small>''In het voorbeeld hiernaast zie je dat ook de gevoeligheid voor de beginwaarde van α wordt bepaald, maar niet die voor x en y. Dat is omdat de ''verplaatsing'' en de ''afwijking'' van het bootje relatief zijn t.o.v. de beginpositie, en dus per definitie beginwaarde 0 hebben. Je ziet bij α ook dat voor invoervariabelen die in het basisscenario 0 zijn een verandering van +20% geen zin heeft, en je dan dus een andere kleine waarde kiest.''</small> | [[Bestand:gevoeligheidsanalyseBootje.png|thumb]]Voer tenslotte een [[gevoeligheidsanalyse]] uit. Rapporteer daarover in de vorm van een [[tabel]] die voor '''elke''' invoervariabele laat zien hoe sterk de uitvoervariabelen veranderen als gevolg van een kleine verandering (typisch +20%) t.o.v. een gekozen basisscenario.<br><small>''In het voorbeeld hiernaast zie je dat ook de gevoeligheid voor de beginwaarde van α wordt bepaald, maar niet die voor x en y. Dat is omdat de ''verplaatsing'' en de ''afwijking'' van het bootje relatief zijn t.o.v. de beginpositie, en dus per definitie beginwaarde 0 hebben. Je ziet bij α ook dat voor invoervariabelen die in het basisscenario 0 zijn een verandering van +20% geen zin heeft, en je dan dus een andere kleine waarde kiest.''</small> | ||
Bij een ''probabilistisch'' model zullen ook bij grote aantallen replicaties de beschrijvende statistieken bij dezelfde invoerparameters nog flink kunnen variëren. De standaarddeviatie σ (over alle replicaties) geeft je een maat voor de te verwachten variatie in het gemiddelde μ van een uitvoervariabele. Als σ groter is dan 20% van μ dan zal gevoeligheidsanalyse met +20% van een invoervariabele niet erg betrouwbaar zijn (tenzij het model '''zeer''' gevoelig is voor die invoervariabele). Kijk in dat geval of meer replicaties σ nog omlaag kunnen brengen (zie hierna). Zo niet, neem dan een grotere verandering t.o.v. het basisscenario, typisch groter dan σ/μ zodat je verwachte verandering buiten de ±σ bandbreedte komt. | Bij een ''probabilistisch'' model zullen ook bij grote aantallen replicaties de beschrijvende statistieken bij dezelfde invoerparameters nog flink kunnen variëren. De standaarddeviatie σ (over alle replicaties) geeft je een maat voor de te verwachten variatie in het gemiddelde μ van een uitvoervariabele. Als σ groter is dan 20% van μ dan zal gevoeligheidsanalyse met +20% van een invoervariabele niet erg betrouwbaar zijn (tenzij het model '''zeer''' gevoelig is voor die invoervariabele). Kijk in dat geval of meer replicaties σ nog omlaag kunnen brengen (zie hierna). Zo niet, neem dan een grotere verandering t.o.v. het basisscenario, typisch groter dan σ/μ zodat je verwachte verandering buiten de ±σ bandbreedte komt. | ||
| Regel 77: | Regel 78: | ||
==Zie ook== | ==Zie ook== | ||
* [[ModEst:Verslaglegging#Verslaglegging over Stap 3|Verslaglegging over Stap 3]] | * [[ModEst:Verslaglegging#Verslaglegging over Stap 3|Verslaglegging over Stap 3]] | ||
* [[ModEst:Conceptueel model|Instructies voor Stap 1 (conceptueel model)]] | |||
* [[ModEst:Operationeel model|Instructies voor Stap 2 (operationeel model)]] | |||
* [[ModEst:Modeltoepassing en interpretatie|Instructies voor Stap 4 (modeltoepassing en interpretatie)]] | |||
Huidige versie van 17 jan 2023 14:29
Werkwijze
- Ga na of de conceptualisatie en operationalisatie goed zijn uitgevoerd.
Controleer in elk geval of elke modelvergelijking vergelijkingen|correct genoteerd is en dimensioneel klopt. - Zet alle onder elkaar (in Word of Powerpoint), maak een nieuw Excelbestand aan, en kopieer de vergelijkingen als afbeelding in het Excelwerkblad.
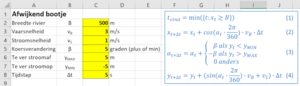
- Maak voor elke exogene variabele een invoerveld. Vermeld daarbij de naam van de grootheid, het symbool van de variabele, en de eenheid. Maak m.b.v. kleur duidelijk welke cellen in het werkblad invoervelden zijn. Voer alvast wat realistische waarden in.Zie afbeelding hiernaast voor een voorbeeld.
- Bij een dynamisch model:

- Voeg een apart invoerveld toe voor de tijdstap Δt.
- Maak onder het invoergedeelte van het werkblad een kolom aan voor de simulatietijd t (typisch kolom A). Zet in de bovenste cel (bijv. A11) de waarde 0, in de cel daaronder de formule =A11+ ... met i.p.v. ... de absolute celreferentie naar de tijdstap Δt. Deze formule kun je dan naar beneden "doortrekken" tot het gewenste aantal tijdstappen.
- Bepaal welke endogene variabelen tijdsafhankelijk zijn. Geef die ieder een eigen kolom parallel aan de simulatietijd.
- Label elke kolom met het symbool (en eventueel ook de eenheid) van de betreffende variabele.
- Maak rechts van de kolommen met dynamische variabelen voor elke statische endogene variabele een cel aan en label die met hun symbool en eenheid. Geef ook deze cellen een kleur zodat duidelijk is dat het uitvoervariabelen zijn. Zie afbeelding hiernaast voor een voorbeeld.
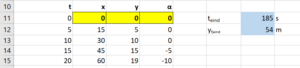

- Implementeer de vergelijkingen.
- Vertaal de wiskundige notatie naar corresponderende formules in Excel. Tip: Noteer eerst op een kladpapiertje een legenda met per variabele de celreferentie (voor de tijdsafhankelijke variabelen de celreferentie voor t=0).
- Doe dit in omgekeerde volgorde. In dat geval zou je, als je invoerwaarden realistisch zijn, ook meteen realistische waarden moeten krijgen.
- Controleer meteen of die waarde klopt met wat je o.b.v. de invoerwaarden zou verwachten. Zo voorkom je een hoop zoekwerk later.
- Bedenk dat voor variabelen die voorraadgrootheden weergeven de beginwaarde voor t=0 ook een invoervariabele is. Geef die cellen daarom dezelfde kleur als de andere invoervelden, en vul een realistische waarde in. Zet de formule voor de vergelijking vervolgens in de rij eronder, en controleer of de berekende waarde realistisch is.
- Zorg m.b.v copy/paste of "doortrekken" dat voor alle variabelen de eerste 3 tijdstappen worden berekend. Controleer opnieuw of de berekende waarden kloppen. Check vooral of de celreferenties naar statische variabelen blijven kloppen. N.B. Bij copy/paste of "doortrekken" gaat het beslist fout wanneer je geen absolute celreferenties gebruikt!
- Visualiseer het dynamische systeemgedrag door de belangrijkste tijdsafhankelijke variabelen in een lijndiagram weer te geven.

- Meestal is een standaard lijndiagram in Excel daarvoor geschikt. Zorg dan wel dat langs de horizontale as de waarden van de simulatietijd t komen te staan i.p.v. de nummers van de tijdstappen. N.B. In het voorbeeld hiernaast was een XY-diagram meer geschikt om de door het bootje afgelegde route te visualiseren.
- Controleer of het systeemgedrag plausibel is, gegeven de invoerwaarden. Bedenk bij welke parameterwaarden je bijzonder gedrag kunt verwachten (bijv. stroomsnelheid = 0, vaarsnelheid = 0 of koersverandering = 0), bedenk hoe de grafiek er dan zou moeten uitzien, en test die hypothese vervolgens door het model met die invoerwaarden door te rekenen.
Probabilistisch model
Bij implementatie van een probabilistisch model zijn nog extra handelingen nodig:
- Run het model een paar honderd keer en verzamel de waarden van elke uitvoervariabele in een gegevensverzameling. In Excel doe je dat m.b.v een gegevenstabel.
- Voor elke uitvoervariabele:
- Bepaal de beschrijvende statistieken van deze gegevensverzameling.
- Geef de gegevensverzameling weer in een histogram zodat de vorm van de kansverdeling zichtbaar wordt.
Dit hoeft niet voor binaire variabelen. In dat geval is het gemiddelde μ gelijk aan de gevraagde kans. - Geef in lijndiagrammen weer hoe μ en σ zich ontwikkelen als functie van het aantal replicaties.
- N.B. De extra formules die je in het Excelwerkblad definieert om beschrijvende statistieken over de replicaties te berekenen zijn geen onderdeel van het simulatiemodel. Deze formules moet je dus niet alsnog in de vorm van vergelijkingen aan het operationele model in §2 van je verslaglegging toevoegen. Je zou ze wel kunnen opnemen in §3, maar omdat het tyisch "standaard" formules voor beschrijvende statistieken zijn, is dat niet nodig.
De door jou gekozen lengte van de tijdstap en de lengte van de simulatieperiode (het aantal rijen voor de tijdsafhankelijke variabelen) kun je wel al in §3 onderbouwen, zéker wanneer de (minimale) simpulatieperiode direct verband houdt met de onderzoeksvraag (bijv. "Hoe ver is het bootje gevorderd na 10 minuten varen?"). In §4 moet je er altijd over rapporteren omdat tijdstap, simulatieperiode, opstarttijd en aantal replicaties onderdeel zijn van het experimenteel ontwerp.
Gevoeligheidsanalyse

Voer tenslotte een gevoeligheidsanalyse uit. Rapporteer daarover in de vorm van een tabel die voor elke invoervariabele laat zien hoe sterk de uitvoervariabelen veranderen als gevolg van een kleine verandering (typisch +20%) t.o.v. een gekozen basisscenario.
In het voorbeeld hiernaast zie je dat ook de gevoeligheid voor de beginwaarde van α wordt bepaald, maar niet die voor x en y. Dat is omdat de verplaatsing en de afwijking van het bootje relatief zijn t.o.v. de beginpositie, en dus per definitie beginwaarde 0 hebben. Je ziet bij α ook dat voor invoervariabelen die in het basisscenario 0 zijn een verandering van +20% geen zin heeft, en je dan dus een andere kleine waarde kiest.
Bij een probabilistisch model zullen ook bij grote aantallen replicaties de beschrijvende statistieken bij dezelfde invoerparameters nog flink kunnen variëren. De standaarddeviatie σ (over alle replicaties) geeft je een maat voor de te verwachten variatie in het gemiddelde μ van een uitvoervariabele. Als σ groter is dan 20% van μ dan zal gevoeligheidsanalyse met +20% van een invoervariabele niet erg betrouwbaar zijn (tenzij het model zeer gevoelig is voor die invoervariabele). Kijk in dat geval of meer replicaties σ nog omlaag kunnen brengen (zie hierna). Zo niet, neem dan een grotere verandering t.o.v. het basisscenario, typisch groter dan σ/μ zodat je verwachte verandering buiten de ±σ bandbreedte komt.
Aan de lijngrafiek van σ als functie van het aantal replicaties kun je zien of de waarde van σ nog veel zal dalen door nog meer replicaties te doen. Als dat niet het geval is, is σ een maat voor de nauwkeurigheid waarmee je μ kunt bepalen. Je kunt in Excel dan het aantal zichtbare decimalen beperken tot die nauwkeurigheid, of μ zelfs af te ronden m.b.v. AFRONDEN(waarde; aantal decimalen). Die (optisch) afgeronde gemiddelde waarden kun je dan gebruiken in je gevoeligheidsanalyse. Die wordt daar niet naukeuriger door, maar wel overzichtelijker.
Verslaglegging
§3 Computationeel model moet:
- logisch voortbouwen op §2 Operationeel model;
- alle vergelijkingen implementeren in Excel;
- deze implementatie duidelijk uitleggen (vooral wanneer je daarvoor specifieke Excelfuncties gebruikt);
- laten zien dat het model voor gegeven invoerwaarden plausibele uitvoerwaarden geeft;
- de resultaten van een gevoeligheidsanalyse weergeven en bespreken.
Als figuren in deze stap moet je (delen van) screen shots van Excel-werkbladen opnemen die duidelijk maken hoe het model in Excel is opgezet. Verder moet je bij een dynamisch model typisch een lijndiagram opnemen dat het systeemgedrag in de tijd weergeeft, en bij een probabilistisch model bovendien een histogram als om een kansverdeling gevraagd wordt.
De resultaten van de gevoeligheidsanalyse geef je typisch weer in één tabel. Bij probabilistische modellen voer je de gevoeligheidsanalyse in elk geval uit op het gemiddelde (μ); hoe de andere beschrijvende statistieken (σ, MIN en MAX) van de uitvoervariabele(n) veranderen bij een verandering in waarde van een invoervariabele kan uiteraard ook informatief zijn.
Checklist voordat je indient
- Check ook Hoofdstuk 1 en Hoofdstuk 2!
- Excelmodel is volledig en overzichtelijk, werkt foutloos en geeft plausibele uitvoer.
- Bij dynamisch model: Systeemgedrag in de tijd wordt gevisualiseerd in lijngrafiek(en) en is plausibel.
- By probabilistisch model: Excel voert voldoende replicaties uit m.b.v. een gegevenstabel, berekent beschrijvende statistieken voor de uitvoervariabelen, en visualiseert de vorm van hun kansverdeling in een histogram.
- Verslaglegging bevat tabel met resultaten van gevoeligheidsanalyse.
- Tekst maakt duidelijk dat het Excelmodel het operationele model correct implementeert.
- Tekst maakt overtuigend duidelijk dat m.b.v. het model de onderzoeksvraag kan worden beantwoord.
- Tekst maakt duidelijk voor welke invoervariabelen het model gevoelig is.
Review
Volg de reviewrichtlijnen voor Stap 3 zoals die op Presto gegeven worden.
Wees specifiek:
- Illustreer overige kritiekpunten met concrete voorbeelden.
Bezwaar aantekenen?
Wanneer je vindt dat je onjuist bent beoordeeld is het raadzaam om bezwaar aan te tekenen.
Hoe je dat doet staat hier uitgelegd.
Let vooral op of je opvolger de noties "onbruikbaar" en "evidente fouten" goed hanteert, en goed onderscheid maakt tussen "primaire" en "overige" kwaliteiten:
Specifieke voorbeelden voor Stap 3
N.B. Als je je bezwaarschrift netjes volgens de richtlijnen indient riskeer je GEEN strafpunten.